生成AIによる対話型サービスとして広く知られるようになった「ChatGPT」だが、そのポテンシャルを惜しみなく発揮するためには、「プロンプティング」(ユーザーからの指示や質問のやり方)以外にも、工夫できることがある。
例えば「パラメータ」と呼ばれる変数を指定することで、出力される回答の傾向をコントロールできる。本稿ではChatGPTですぐに試してみたくなるパラメータについて、3つの例を紹介しよう。
●パラメータとは
そもそもパラメータとは、「補助的に使われる変数」のことを指す言葉だ。大規模言語モデルの文脈では、出力の方向性を補助的に決める数値を意味する。ChatGPTのようなサービスは、大量のパラメータによって制御されていると考えられ、APIを活用するサービスの設計ではこれらの制御も欠かせない。
ただし、大前提としてWebサービスとして提供されているChatGPTに関しては、こうしたパラメータの存在について明かされているわけではない。ChatGPT自身が答えてくれることもあるが、あくまでも、本稿で紹介する5つのパラメータについては、多くのユーザーが経験則で導いてきたものを整理したものとして、自己責任にて試してほしい。
●(1)「max_length」や「max_tokens」:文の長さを制御
1つ目は、出力されるテキストの長さを調整するパラメータだ。似たような制御が行えるパラメータがいくつかあると考えられているが、今回はそのうちの「max_length」と「max_tokens」を試してみた。
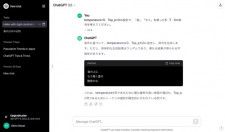
実際に、プロンプトの中に「max_length=5の設定で」のように指示を加えてみたところ、数値の変化とともに以下のような変化があった。
なお、「max_length=○○」で指定する値は、英単語のスペルの数にひもづく。一方、「max_tokens=○○」で指定する値は、「トークン(スペースなどで区切られた単語や、句読点そのものなど)」の数に連動するとされる。どちらも「文字数」を精密に制御できるわけではなく、数値の調整をしながら目的の長さに近づける試行錯誤は必要のようだ。
ちなみに、日本語でmax_lengthを試しても、ある程度の長さのコントロールならばできそうだった。例えば、キャッチコピーのヒントを探りながら、候補を練る際などに、こうしたパラメータを調整して、おおむねの文字数を伸び縮みさせていくアプローチは有効活用できるかもしれない。
●(2)「n」:候補の数を指定
2つ目は、列挙される出力の数をコントロールするパラメータ「n」だ。こちらもプロンプトの中に「n=3の設定で」を含めるだけで簡単に利用できる。例えば、「n=3の設定で、日本の春に咲く野草の名前を挙げて」と指示すると、代表的な候補を3つ挙げてくれるという具合だ。
ただし、この程度の挙動は普通にテキストで「〜を3つ挙げて」と指定するのとさほど変わらない。そのため、筆者が検証した範囲では、実用性がどのくらいあるのかは、評価できなかった。
●(3)「Temperature」または「Top_p」:ランダムさを調整
3つ目は、「Temperature」や「Top_p」といったパラメータだ。それぞれ一般的に「0〜1」の値(小数点もOK)が取られ、値が小さいほど、後ろに続く可能性が高い単語が選ばれて、堅実なテキストが出力されることになる。反対に値が大きいほど、“創造性の高い”=ランダム性の高い出力が期待できるようになるとされる。こちらも実際に試してみよう。
これらの出力された句を見てみると、「岩」+「セミ」とキーワードが絞られて、閑さや(しずけさや)→「静寂」との連想に至るのは、どちらも共通している。一方で、両パラメータが0のときには「静寂かな」というよくありそうな詠嘆が選択されており、両パラメータが1のときには「静寂の中」という崩した表現への挑戦が見られる印象だ。
もちろん試行回数が少ないため、どの程度がパラメータの影響なのかは断言できないが、こうした傾向があると思っておくと、パラメータを試しながら遊びやすくなるかもしれない。
他にもChatGPTで使えるといわれているパラメータはいくつも存在する。例えば、本稿では割愛するが、興味がある方は「frequency_penalty」や「presence_penalty」についても調べてみると面白いだろう。

![ライフハッカー[日本版]](https://img.news.goo.ne.jp/image_proxy/compress/q_80/picture/lifehacker/s_lifehacker_2404-what-it-airchat-the-talking-social-network.gif)



![ライフハッカー[日本版]](https://img.news.goo.ne.jp/image_proxy/compress/q_80/picture/lifehacker/s_lifehacker_2404apple-released-details-about-its-new-mm1-ai-model.png)

![ライフハッカー[日本版]](https://img.news.goo.ne.jp/image_proxy/compress/q_80/picture/lifehacker/s_lifehacker_2404-lht-notta.png)